Lokale KI-Modelle mit OpenWebUI und Ollama
Step-by-Step-Guide

Künstliche Intelligenz ist längst nicht mehr nur ein Trend – sie verändert grundlegend, wie wir arbeiten, kommunizieren und Entscheidungen treffen. Doch während KI immer leistungsfähiger wird, bleibt eine zentrale Herausforderung: Wie können wir diese Technologie sinnvoll nutzen, ohne uns dabei in Abhängigkeit von Cloud-Diensten zu begeben oder Datenschutzrisiken einzugehen?
Genau hier setzten wir an. Wir wollten eine Lösung, die nicht nur flexibel und leistungsfähig ist, sondern uns gleichzeitig die volle Kontrolle über unsere Daten und Prozesse gibt. Mit OpenWebUI und Ollama haben wir genau das gefunden. Diese Kombination ermöglicht es uns, KI-Modelle lokal zu betreiben, ohne auf externe Anbieter angewiesen zu sein – schnell, sicher und ohne versteckte Kosten.
In unserer firmeninternen AI Domain haben wir eine klare Mission: KI sinnvoll in unsere internen Prozesse und Kundenprojekte zu integrieren – effizient, datenschutzkonform und mit echtem Mehrwert. Wir testen neue Tools, evaluieren deren Nutzen und sorgen dafür, dass unsere KI-Strategie nachhaltig und skalierbar bleibt. Dabei geht es nicht nur um Technologie, sondern darum, wie KI uns tatsächlich unterstützt – sei es durch Automatisierung, smartere Workflows oder innovative Lösungen für unsere Kunden.
Unser Ziel ist es, KI so einzusetzen, dass sie uns unabhängiger, schneller und besser macht. OpenWebUI und Ollama sind für uns ein großer Schritt in diese Richtung. Und weil wir von diesem Setup überzeugt sind, möchten wir unsere Erfahrungen teilen. Denn leistungsstarke KI muss nicht in der Cloud liegen – sie kann direkt vor Ort laufen, auf eigener Hardware, mit voller Kontrolle.
Es ist Zeit, KI nach unseren eigenen Vorstellungen zu nutzen und nicht nach den Vorgaben der großen Anbieter.
In diesem Blogpost zeige ich Dir Schritt für Schritt, wie Du Dein eigenes lokales KI-System aufsetzen kannst und welche Vorteile dies mit sich bringt.
Warum ein lokales Setup?
Die meisten KI-Modelle laufen heutzutage über Cloud-Dienste wie OpenAI, Google Cloud oder Microsoft Azure. Diese Dienste bieten immense Rechenleistung und einfache Integration, haben aber auch Nachteile:
-
Datensicherheit: Sensible Daten werden über das Internet übertragen und möglicherweise auf fremden Servern gespeichert. Dies widerspricht den Anforderungen von eggs, bei denen Datenschutz oberste Priorität hat.
-
Kosten: Cloud-Dienste können sehr teuer werden, vor allem bei hohem Datenvolumen oder intensiver Nutzung.
-
Verfügbarkeit: Du bist von der Zuverlässigkeit externer Anbieter abhängig. Serverausfälle können Projekte zum Stillstand bringen.
-
Geschwindigkeit: Die Kommunikation mit entfernten Servern kann zu Verzögerungen führen, die insbesondere bei Echtzeitanwendungen problematisch sind.
Ein lokales Setup, wie das hier vorgestellte, löst all diese Probleme. Es entspricht den Zielen der AI Domain von eggs, innovative und sichere KI-Lösungen bereitzustellen, die sowohl datenschutzkonform als auch ressourcenschonend sind. Es bietet:
-
Volle Kontrolle: Daten bleiben lokal und werden nicht extern gespeichert.
-
Kosteneffizienz: Bezahlte KI Dienste werden schnell teuer.
-
Geschwindigkeit und Flexibilität: Schnelle Verarbeitung ohne Abhängigkeit von Dritten.
Voraussetzungen für Dein lokales KI-Setup
Hardware
Bevor du durchstartest, überprüfe, ob dein Rechner die folgenden Mindestanforderungen erfüllt:
-
Apple Silicon oder Nvidia GPU für maximale Performance.
-
RAM:
8 GB: Ausreichend für kleinere Modelle
16 GB: Empfohlen für reibungslose Verarbeitung von 13B-Modellen
32 GB: Optimal für größere Modelle wie 33B
Profi-Tipp: Mit 16 GB RAM kannst du flexibel zwischen kleineren und mittleren Modellen wechseln, ohne Kompromisse.
Software
-
Eine saubere, isolierte Umgebung einrichten
Rancher Desktop herunterladen – alles, was du brauchst, in einer All-in-One-Lösung.
-
Ollama installieren: Download Ollama auf GitHub für den Einsatz von Llama 3.3, Mistral, Gemma 2 und anderen großen Sprachmodellen.
-
Optional: Nutze Continue, um deine Entwicklungsumgebung zu erweitern.
Schritt-für-Schritt-Anleitung: Einrichtung von OpenWebUI und Ollama
1. Eine saubere, isolierte Umgebung einrichten
Rancher Desktop herunterladen – alles, was du brauchst, in einer All-in-One-Lösung.
Das entsprechende Betriebssystem auswählen und installieren.
2. Ollama installieren
Lade Ollama herunter und installiere es auf deinem Rechner. Dieser Schritt bildet die Grundlage für das gesamte Setup.
Download Ollama auf GitHub für den Einsatz von Llama 3.3, Mistral, Gemma 2 und anderen großen Sprachmodellen.
Auf dem Github Repository, nach unten zu den entsprechenden Versionen für das Betriebssytem navigieren und installieren.
3. Ordnerstruktur und Docker Compose Datei erstellen
Erstelle einen neuen Ordner auf Deinem Computer, in dem alle Konfigurationsdateien gespeichert werden. In diesem Ordner legst Du eine neue Datei an, die Du compose.yml nennst. Kopiere den folgenden Text in die Datei:
webui:
image: ghcr.io/open-webui/open-webui:main
volumes:
- open-webui:/app/backend/data
ports:
- 3000:8080
environment:
- WEBUI_AUTH=false
- SAFE_MODE=true
- ENABLE_COMMUNITY_SHARING=false
- OLLAMA_BASE_URL=http://host.docker.internal:11434
restart: unless-stopped
volumes:
open-webui: {}
4. Docker Compose starten
Öffne ein Terminal, navigiere zu dem Ordner mit der compose.yml und starte den Dienst mit:
5. OpenWebUI aufrufen
Öffne Deinen Browser und rufe http://localhost:3000 auf. Voilà! Du hast jetzt Zugriff auf Dein eigenes lokales OpenWebUI-Interface.
Modelle hinzufügen und nutzen
Modell installieren
Überprüfe, ob das Modell verfügbar ist. Die Quelle (z. B. „von Ollama beziehen“) wird angezeigt. Stelle sicher, dass du eine aktive Internetverbindung hast, um das Modell herunterzuladen.
Modellauswahl:
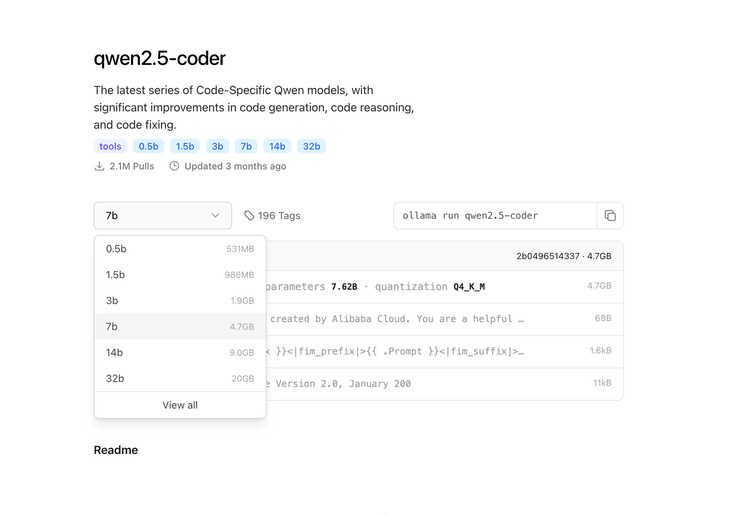
Suche in der Benutzeroberfläche nach dem gewünschten Modell. Hier erkläre ich nochmal, worauf es hier ankommt. Wenn Du Dir die verschiedenen Versionen von Qwen2.5 ansiehst, fällt sofort auf, dass die Modelle in ihrer Größe stark variieren – von kompakten 398 MB bis hin zu beeindruckenden 47 GB. Aber was steckt dahinter, und warum sind die Unterschiede so groß?
Größe vs. Leistung
Die Größe eines Modells hängt direkt mit der Anzahl seiner Parameter zusammen. Parameter sind die Bausteine, die ein Modell verwendet, um Sprache, Kontext und Bedeutung zu verstehen und zu generieren. Ein Modell mit 0.5B (500 Millionen) Parametern ist kleiner und schneller, aber weniger leistungsstark. Auf der anderen Seite bietet ein Modell mit 72B (72 Milliarden) Parametern deutlich mehr Präzision und Kontextverständnis – allerdings auf Kosten von Speicherplatz und Rechenleistung.
Was bedeutet das für Dich?
Die Wahl des Modells hängt von Deinem Anwendungsfall ab:
-
Kleinere Modelle (0.5B - 3B): Ideal für einfache Aufgaben oder Geräte mit begrenzten Ressourcen.
-
Mittelgroße Modelle (7B - 14B): Ein guter Kompromiss zwischen Leistung und Hardwareanforderungen.
-
Große Modelle (32B - 72B): Perfekt für komplexe Anwendungen, bei denen maximale Genauigkeit und Kontexttiefe gefragt sind – aber nur, wenn Du die nötige Hardware hast.
-
Modell herunterladen:
-
Klicke auf das Modell, um es auszuwählen. Wenn der Download nicht automatisch beginnt, suche nach einem Button oder einer Option wie „Herunterladen“ oder „Modell abrufen“.
-
In einigen Fällen wird gefragt, ob das Modell lokal gespeichert oder temporär genutzt werden soll (siehe „Temporary Chat“ im Screenshot). Wähle die Option aus, die Deinen Bedürfnissen entspricht.
-
Chatten mit dem Modell
Sobald das Modell installiert ist, kannst du direkt mit ihm kommunizieren.
3. Optional: Integration in deine Entwicklungsumgebung
Für Entwickler:innen bietet dieses Setup einen besonderen Vorteil: Mit dem Continue Plugin kannst du die Modelle in Entwicklungsumgebungen wie IntelliJ oder VS Code integrieren: Nutze Continue, um deine Entwicklungsumgebung zu erweitern.
{
"models": [
{
"model": "AUTODETECT",
"title": "Ollama",
"apiBase": "http://localhost:11434",
"provider": "ollama"
}
],
"customCommands": [
{
"name": "test",
"prompt": "{{{ input }}}\n\nWrite a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.",
"description": "Write unit tests for highlighted code"
}
],
"tabAutocompleteModel": {
"title": "qwen2.5-coder", ///namen anpassen
"provider": "ollama",
"model": "qwen2.5-coder" ///namen anpassen
},
"embeddingsProvider": {
"provider": "ollama",
"model": "nomic-embed-text"
},
"contextProviders": [
{
"name": "code",
"params": {}
},
{
"name": "docs",
"params": {}
},
{
"name": "diff",
"params": {}
},
{
"name": "terminal",
"params": {}
},
{
"name": "problems",
"params": {}
},
{
"name": "folder",
"params": {}
},
{
"name": "codebase",
"params": {}
}
],
"slashCommands": [
{
"name": "edit",
"description": "Edit selected code"
},
{
"name": "comment",
"description": "Write comments for the selected code"
},
{
"name": "share",
"description": "Export the current chat session to markdown"
},
{
"name": "cmd",
"description": "Generate a shell command"
},
{
"name": "commit",
"description": "Generate a git commit message"
}
],
"experimental": {
"quickActions": [
{
"title": "Detailed explanation",
"prompt": "Explain the following code in detail, including all methods and properties.",
"sendToChat": true
}
]
}
}
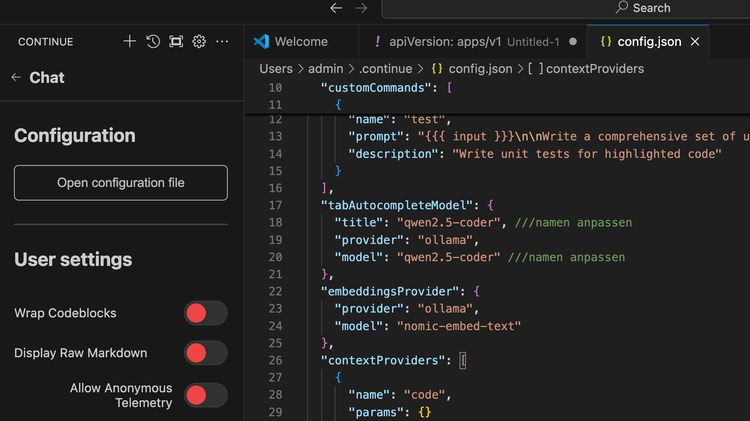
!!Bitte bachten!!
Der Modellname muss evtl angepasst werden, Stellen sind kommentiert – eingestellt ist es auf qwen-coder2.5
Abschließend muss die Config noch gespeichert werden.
Fazit: Warum eggs dieses Setup liebt
Ein lokales KI-Setup wie dieses ist für uns bei eggs nicht nur eine technische Entscheidung, sondern ein echter Gamechanger. Wir wollten eine KI-Infrastruktur, die nicht nur leistungsstark, sondern auch datenschutzkonform und kosteneffizient ist – und genau das haben wir mit OpenWebUI und Ollama erreicht.
Was uns besonders überzeugt hat: Wir sind nicht mehr von Cloud-Anbietern abhängig. Keine versteckten Kosten, keine plötzlichen AGB-Änderungen, keine Datenschutzrisiken. Stattdessen läuft alles auf unserer eigenen Infrastruktur, schnell, zuverlässig und unter voller Kontrolle. Und das Beste? Die Performance ist der Wahnsinn. Kein Warten auf externe Server, kein Lag – einfach direktes Arbeiten mit KI, so wie es sein sollte.
Aber es geht nicht nur um uns. Dieses Setup hilft uns auch dabei, unsere Kunden besser zu unterstützen. Projekte laufen effizienter, sensible Daten bleiben geschützt, und wir können maßgeschneiderte KI-Lösungen entwickeln, ohne Kompromisse eingehen zu müssen.
Für alle, die sich mit KI beschäftigen, ist das der nächste logische Schritt. Wer einmal erlebt hat, wie flüssig und flexibel eine eigene KI-Umgebung läuft, will nicht mehr zurück zu teuren, undurchsichtigen Cloud-Lösungen. Also, wenn Ihr überlegt, Eure KI-Strategie auf das nächste Level zu heben: Probiert es aus. Wir haben es getan – und es hat sich gelohnt!